



Symbols, Productions and Grammars
1 of 3

It’s been a while since my last post. Almost a year actually. Since then, I’ve fallen in love with compilers again, and contributed about a dozen PRs to LLVM libc——something I’m particularly proud of. But that’s not why I’m writing today.
I built a parser generator, and I want to talk about it for a bit. Well, not a bit. This is the first of three Substack posts on parser theory and parser generators.
Why?
A self-referential documentation of the concepts I learned and the code that resulted from it.
A less-than formal description of LR(1) parsing and parse-table generation.
To be clear, I’d absolutely refer you to the books: “Engineering A Compiler” (by Keith D. Cooper and Linda Torczon) and “Compilers: Principles, Techniques, and Tools” (you know the one!). They go into a lot more detail on the above material than what these posts can suffice. A lot more detail.
Still, I found implementing the described algorithm to be non-trivial. Perhaps it was the formal language, or maybe the language-agnostic nature of the pseudocode. That, quite literally, is the point of these Substack posts: to discuss the direct implementation of the parse tables generation algorithm in C++.
Here it is for your reference: https://github.com/wldfngrs/parser-generator
In 878 lines of code, the repository takes a grammar specification for an LR(1)1 grammar as input and generates a C++ header file containing tables and helper structs for parsing2 the LR(1) grammar.
Let’s begin.
1 Representing Grammar in code
Consider the ‘parentheses’ grammar3, as described in Section 3.4 of “Engineering a Compiler”:
Goal > List
List > List Pair | Pair
Pair > ( Pair ) | ( )Where “>” marks the end of a production’s LHS4 (and the beginning of a production’s RHS), and “|“ represents alternation (different possible expansions for a non-terminal).
A valid representation of this grammar specification as input to the parser-generator5 program must contain a terminal definition block, a blank line, and a rule/production block as follows:
t_EOF
t_LP
t_RP
Goal > List
List > List Pair
List > Pair
Pair > t_LP Pair t_RP
Pair > t_LP t_RPEach of these “words” are symbols6 in the grammar. Specifically, the symbols prefixed by ‘t_’ are terminal7 symbols. Symbols not prefixed by ‘t_’; List, Pair, Goal, are non-terminal8 symbols. In this grammar specification, ‘t_LP’ and ‘t_RP’ represent the left-parentheses and right-parentheses characters/tokens respectively.
‘t_EOF’ represents the lookahead9 symbol of the goal production10. The parser-generator expects this goal production lookahead11 symbol to be defined on the first line of the terminal definition block. Likewise, it expects the goal production to be defined on the first line of the rules/productions block.
1.1 ParseGen class
The parser generator is structured as a class; ParserGen. The class constructor opens an input stream to the grammar specification file and stores the contents in the std::string grammar_txt.
You’d notice the use of std::string_view objects throughout the codebase. Many member variables reuse the same string literals as keys or values in std::unordered_map or std::unordered_set objects, or as elements in dynamic arrays (std::vectors). By inserting these literals once in a string interning structure (aptly named strings) and returning pointers to them when needed, memory consumption is significantly reduced.
1.1.1 Function Overview: get_terminals_and_productions()
This member function parses the grammar specification stored in grammar_txt, returning a boolean value indicating parse success (true) or failure (false). It scans grammar_txt line-by-line, classifying each line as either a terminal definition or a production12 rule while handling and reporting errors in the specification syntax.
Parsing Terminals
While parsing_terminals is true, the function checks for valid terminal definitions (lines beginning with ‘t_’).
For each valid definition, whitespace-separated fields (terminal name, precedence and associativity) are extracted and contained in term_info; a std::vector<std::string>. The maximum number of expected fields (elements in term_info) is three.

If the size of term_info is one, only one field is explicitly declared (that is, a terminal without precedence or associativity). In this case, a Terminal instance is created with default precedence; 0, default associativity; “n” (non-associative), and added to the member variable terminals; a std::unordered_set of Terminal objects.

If the size of term_info is two, the second field represents either precedence or associativity. If it is not an integer, it is checked for a valid associativity value (“n”, “l” or “r”); otherwise, an error is reported.
If the second field is valid (either an integer for precedence or a valid associativity value), a Terminal object is created with a precedence of 0 (default) if associativity is specified or “n” associativity (default) if precedence is specified instead. The Terminal object is added to terminals.

If term_info size is three, the second field is precedence, and the third is associativity. Likewise, a Terminal object is created with the associated fields and added to terminals.
Once terminals are done (blank line is scanned), parsing_terminals is set to false, and if there were no errors while parsing terminals, parsing_productions is set to true, signifying the start of the rules/productions block.
Parsing Productions
Production rules are processed in the format: LHS > RHS; where LHS is the string of characters extracted until the first whitespace, and RHS is the string of characters that follow the delimiter string (“ > ”). The LHS symbol, once extracted, is added to the member variable non_terminals; a std::unordered_set of std::string_view objects.
The production rule format is then validated, ensuring the expected delimiter string (“ < ”) follows the extracted LHS symbol.

Next, the first terminal in RHS is identified and added to the member variable firsts. firsts is a std::unordered_map that uses a std::string_view object as key (the LHS non-terminal symbol), and a std::unordered_set of std::string_view objects (the first terminal symbols in each RHS that derives the LHS) as value. The next post in this series explains why we collect this firsts information.
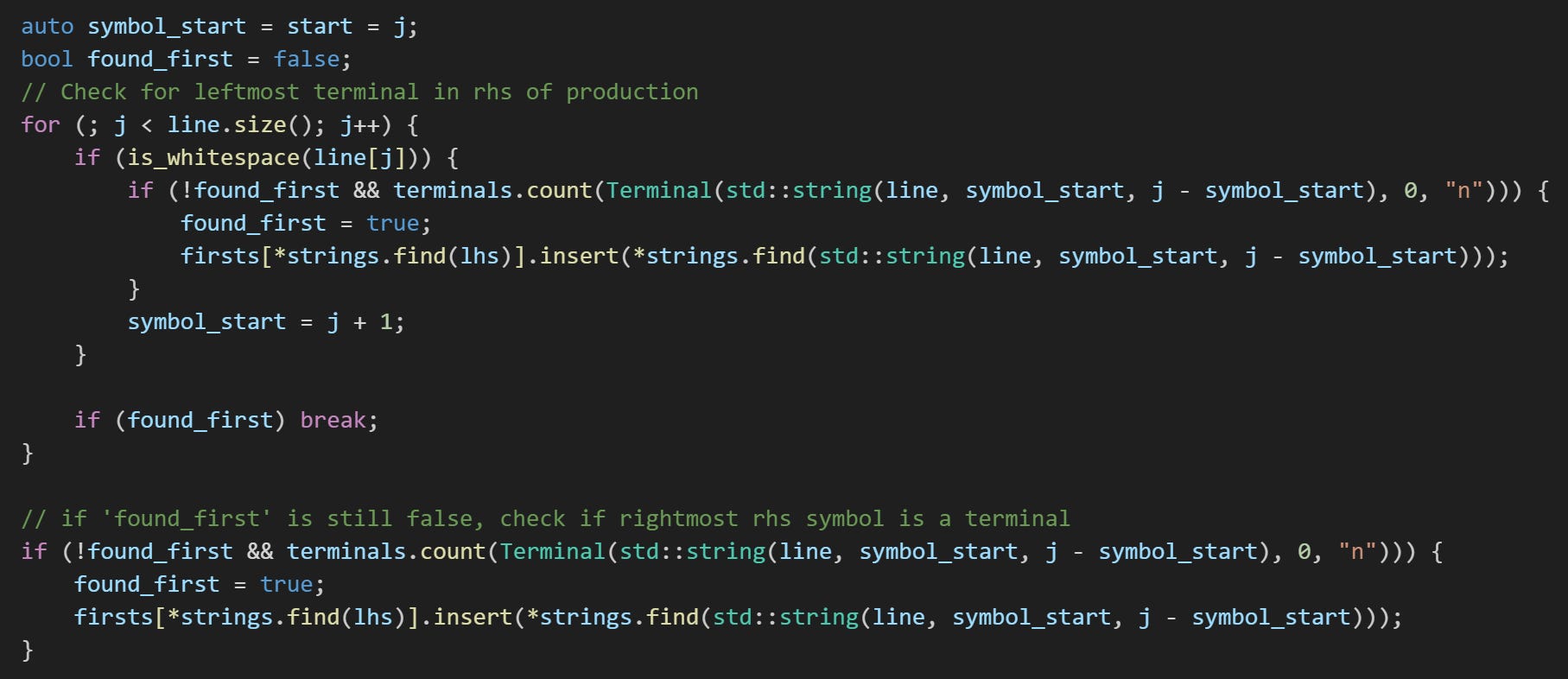
Note that, more than one RHS can derive a single LHS. For example;
Pair > t_LP Pair t_RP
Pair > List t_RP t_LPIn the first production for the Pair LHS, t_LP is the first terminal symbol. Contrarily, in the second production for the same Pair LHS, t_RP is the first terminal symbol. Both terminal symbols have to be stored as firsts for that single LHS, hence the use of a std::unordered_set as value to the LHS non-terminal key; the unique first terminal symbols in the RHS.
Sometimes, it is necessary to assign explicit precedence to a production to enforce correct parsing order. In a mathematical expression grammar, for example, the production defining Unary expressions—such as negation—requires precedence to ensure that a minus token binds more tightly to operands than binary operators like addition, subtraction or multiplication.
If a RHS ends in a number, that number is treated as the production’s precedence. Otherwise, the precedence defaults to 0. The RHS, excluding the precedence value if explicitly specified, is extracted and mapped to the assigned precedence (or 0 if none is provided) in the member variable production_precedence; a std::unordered_map.
Finally, if error_in_get_terminals_and_productions is still false at this point, the LHS and RHS are added to the member variable productions; a std::unordered_map, as a key-value pair. Since a single LHS can have multiple RHS derivations, productions uses a std::string_view as key, and a std::vector<string_view> as value. Each element in the vector represents a valid RHS for the corresponding LHS.

1.1.2 Function Overview: check_symbols_in_productions()
This member function validates the production rules extracted during get_terminals_and_productions() by ensuring that all symbols in the RHS are terminal symbols or valid LHS non-terminal symbols, while detecting REDUCE-REDUCE conflicts.
It returns true if all symbols in the production rules are valid and no REDUCE-REDUCE conflicts exist. Otherwise, it returns false.
For each production in productions, the RHS symbols are split using whitespaces as a delimiter and checked for validity.

If a symbol is neither a terminal or non-terminal, it sets found_invalid_symbol flag to true and the error is reported. Otherwise, the symbol is appended to the std::string local variable symbols_in_rhs which reconstructs the RHS.
REDUCE-REDUCE conflicts
After confirming the validity of all symbols in a production’s RHS and reconstructing the RHS in symbols_in_rhs, the function checks whether symbols_in_rhs exists in the local valid_prod; a std::unordered_map that associates each unique RHS (std::string_view) to it’s corresponding LHS (std::string_view).

If symbols_in_rhs (the reconstructed RHS) is not found in valid_prod, it is added, mapping it to the current production’s LHS. However, if symbols_in_rhs already exists in valid_prod, a REDUCE-REDUCE conflict is detected and reported, as this indicates that two different LHS non-terminals can be mapped to the same RHS, leading to grammar ambiguity. In this case, the check has failed and the function returns false.
Otherwise, if all symbols were valid and no REDUCE-REDUCE conflicts occurred, the function returns true.
Next, generating the canonical collection of states.
An LR(1) grammar is a context-free grammar that can be parsed using an LR(1) parser, which processes input left-to-right (L) and constructs a rightmost derivation (R) in reverse using one lookahead token (1). This means that at each step, the parser decides whether to SHIFT (read more input) or REDUCE (apply a production rule) based on the current parser state and a single lookahead symbol.
In the domain of computing, parsers are software programs that compilers use to reason about textual input. While a grammar defines “valid” textual input, a parser analyzes that textual input and validates or invalidates it, according to that defined grammar.
A grammar defines the “rules“ for forming valid “sentences“ in a language; specifying allowed symbols, their combinations, and order.
LHS is the Left Hand Side of a production/rule. RHS is the Right Hand Side of a production/rule.
A parser generator creates a parser that implements state-based logic for validating textual input according to a given grammar specification.
Symbols are terminals or non-terminals in a grammar.
Terminals are the smallest, indivisible units of a language. They are base symbols of a grammar that appear in textual inputs and cannot be replaced or expanded further.
Non-terminals are replaceable symbols that represent groups of other symbols (terminals or non-terminals) in production rules.
The lookahead is the next occurring terminal token in the input that the parser examines to decide what action to take——SHIFT or REDUCE.
The goal production is the highest-level structure that the parser expects to derive from the input. It’s LHS is the root of the derived parse tree, and can’t be reduced further. Deriving this production means the textual input is valid.
The goal production lookahead is the lookahead symbol of the goal production. Typically an end-of-file terminal token.
A production defines how a non-terminal can be replaced with a sequence of terminals and/or non-terminals.
This was nice, have you seen matklad's post on ideas for a modern parser generator?: https://matklad.github.io/2018/06/06/modern-parser-generator.html