



Items, Handles, Canonical Sets and Collections
2 of 3

The previous post detailed representing the grammar specification in code. That is, extracting terminals, non-terminals, and productions into specified data structures. This post explains how to build the canonical collection of sets from the extracted information. To start with, I’d suggest you read the third chapter of ‘Engineering a Compiler’ by Keith D. Cooper and Linda Torczon. The writings here are in no way all-encompassing and would serve better as an accompaniment/expansion of the ideas expressed in the chapter.
1 Building the Canonical Collection of Sets
The canonical collection of sets consists of all the possible stages of the parser for a grammar. These stages are distributed as “item” sets; each set containing “items” that represent a parsing context.
An item represents a parsing context1 by storing the specific grammar production being parsed, how much of the production has been parsed so far, and a single terminal (the lookahead symbol) that follows this production in parsing. Essentially, an item is a “snapshot of the parser’s state”; what the parser has seen and what it expects next.
Take this production for example:
E > T +A RHS non-terminal “T”, followed by the RHS terminal “+”, that derives the LHS non-terminal “E”. This production, alongside a lookahead symbol “a”, generate three possible items distinguished by a marker(*) position:
[E > *T +, a]: Indicates that the parser recognizing a “T” would be a step toward deriving an “E”. Such an item is called a possibility because it represents a possible valid parse that the parser may follow.
[E > T *+, a]: Indicates that the parser has progressed from state [E > *T +, a] by recognizing “T”. This recognition makes the item partially complete because a part of the item’s RHS has been recognized.
[E > T +*, a]: Indicates that the parser has recognized both “T” and “+” in that order. If the lookahead symbol (next terminal) is “a”, then the item is a handle and the parser can reduce “T +” to “E”. Such an item is complete.
The * encodes left context; the portions of the production that have been recognized, while the lookahead symbol encodes one symbol of right context.
In the parser-generator, items are objects of the following type:

Where production is a std::vector of the symbols in the item production, position is an index into the std::vector indicating the parser progress (just like *). The production RHS symbols start from index 1 (index 0 is the production LHS).
lookahead is the terminal symbol that follows the production in that parsing context. production_precedence is the precedence value associated with the production, extracted during get_terminals_and_productions().
1.1 Function Overview: build_cc()
This member function constructs the canonical collection of sets of items by iteratively computing the transitions between sets of items. The canonical collection is represented as a std::unordered_map, where the keys are std::unordered_set objects containing items, and the values are CanonicalCollectionValue struct instances.
CanonicalCollectionValue is a two-member struct:
The state as an unsigned integer, representing the set’s unique identifier.
A boolean flag identifying whether the state has been processed in build_cc().
Building the canonical collection in build_cc() relies on two operations: taking a closure (closure_function()), and computing a transition (goto_function()).
1.1.1 Function Overview: closure_function()
Given a core set of items, this function adds to that set any related items that the core set “implies”.
Here’s the algorithm in pseudocode, where ‘s’ is a canonical set of items:
closure(s):
while there's items left to be processed in s:
for each item [A > B *C d, t] in s:
for each production [C > y] that derives C:
for each terminal 'b' in the set FIRSTS(dt):
add the item [C > y, b] to the set s
return sStarting with a single item ‘I’, how does the closure function compute the items that item ‘I’ implies?
If the ‘*’ marker in an item ‘I’ precedes a non-terminal, C, the function collects all the rules/productions that derive that non-terminal, C. It then builds an item for each of those productions by inserting a ‘*’ marker at the start of the production’s RHS, and adding the appropriate lookahead symbol (the first terminal that appears in the symbols following C in the starting item ‘I’; FIRSTS). These items are added to the item set “s”, as the items implied by item ‘I’.
For example, let ‘I’ be the item [Goal > *List Pair, EOF].
From the ‘parentheses’ grammar2, two productions can derive List (the non-terminal following the ‘*’ marker):
‘List > List Pair’
‘List > Pair’
Adding the first terminal that appears in the production for Pair3 (the symbol following List in ‘I’) as lookahead, the following items are therefore implied by ‘I’: [List > *List Pair, ‘(’] and [List > *Pair, ‘(’].
Here’s the closure function implementation in C++:
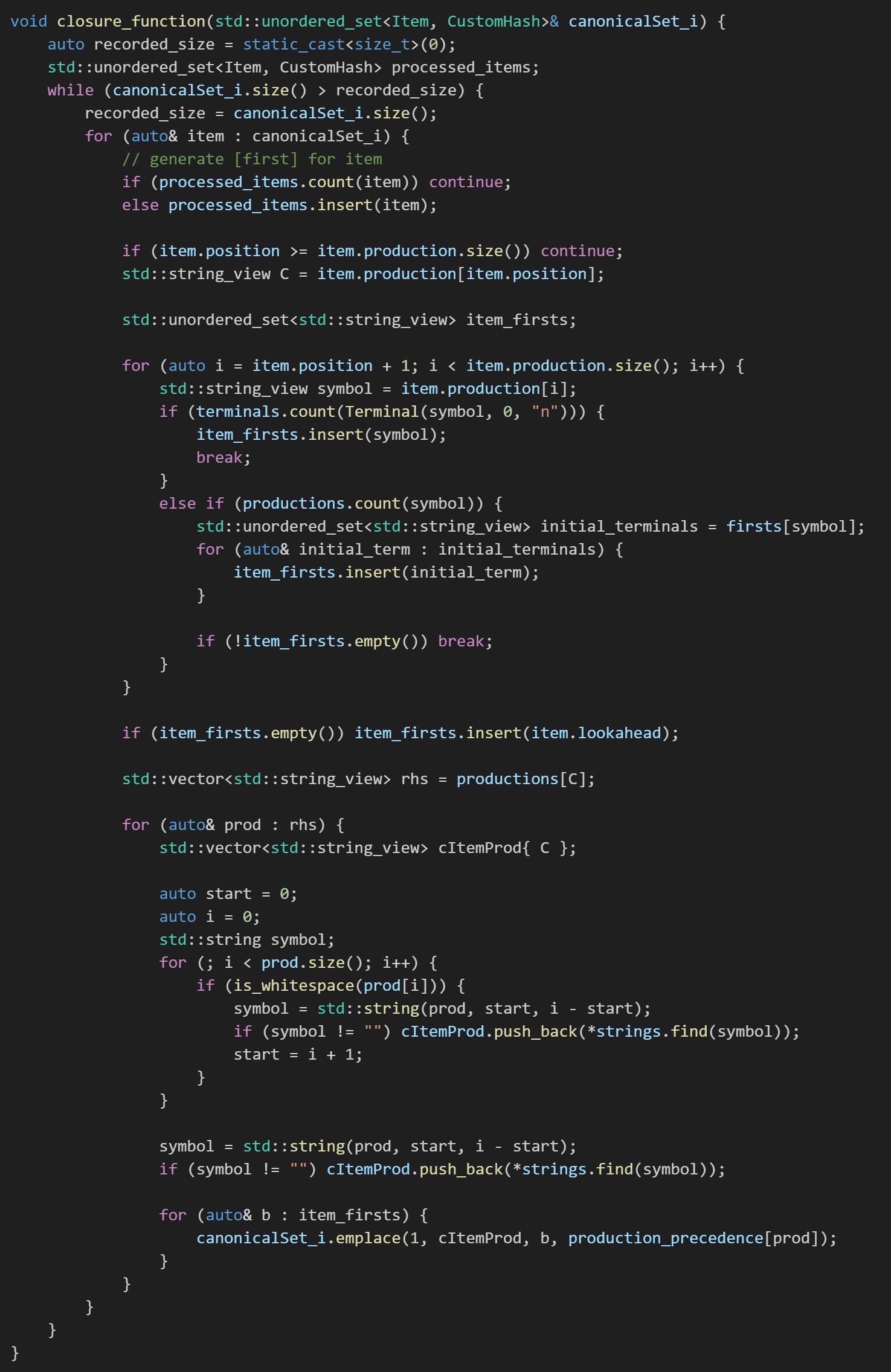
It takes the core set of items; canonicalSet_i, a std::unordered_set, as argument, iterating over the items in this set. For each item, the first for-loop generates the FIRSTS set; item_firsts. The routine is simple. It checks the symbol following C. If it is a terminal, it adds that terminal to item_firsts and exits the for-loop. If it is a non-terminal/production LHS, it gets it’s “firsts” (the terminals that appear first/leftmost terminal in the production(s) RHS. Recall that this firsts data was initialized in get_productions_and_terminals()) and adds them to item_firsts. If item_firsts is still empty at the end of this iteration, it moves one symbol to the right and repeats the process.
If at the end of the initial for-loop item_firsts is still empty (that is, no terminals occurring between C and the end of the item production), the item lookahead is added to item_firsts.
The second for-loop generates items for each production that derives C, adding all the elements of item_firsts as lookaheads for each generated item.
Note that in C++, std::unordered_sets undergo rehashing when new elements are inserted beyond its current capacity. During rehashing, elements are restructured, and all iterators become invalid. In situations——like this one——of iterating over the std::unordered_set elements, while simultaneously inserting new elements, newly inserted elements may never be visited in the current iteration.
To ensure that every single element (item) in canonicalSet_i is processed/visited:
The actual closure operation is enclosed within a while loop that monitors the size of canonicalSet_i.
Before each closure operation, the number of elements in canonicalSet_i is recorded.
After the closure operation, if the size of canonicalSet_i is greater than the recorded_size, new items were added, and another iteration is required to process them.
The loop continues until no new items are added to canonicalSet_i, ensuring all items are visited. Additionally, when an item is visited in the closure operation, it is marked as processed by inserting it into processed_items; a std::unordered_set of items. During the iterations, processed items are skipped, preventing redundant computations.
1.1.2 Function Overview: goto_function()
Given a parser state (a set of items), and some grammar symbol, x, this function computes the next set of items that would result from recognizing an x.
Here’s the algorithm in pseudocode, where ‘s’ is a canonical set of items, and ‘v’ is a grammar symbol:
goto(s, v):
define an empty canonical set 'moved'
for each item 'i' in s:
if the form of 'i' is [A > B *v D, e] then:
shift the * marker one symbol to the right than
add this item with the updated marker position to moved
closure(moved) The goto function iterates over all the items in a given set, identifying items where the marker ‘*’ precedes the specified symbol ‘v’. When such an item is found, the marker is shifted one symbol to right, creating a new item that reflects this parse progress. The new, updated item is added to the canonical set moved. At the end of the iteration, the goto function invokes the closure function on moved, to compute all possible derivations from the updated set.
Here’s the goto function implementation in C++:
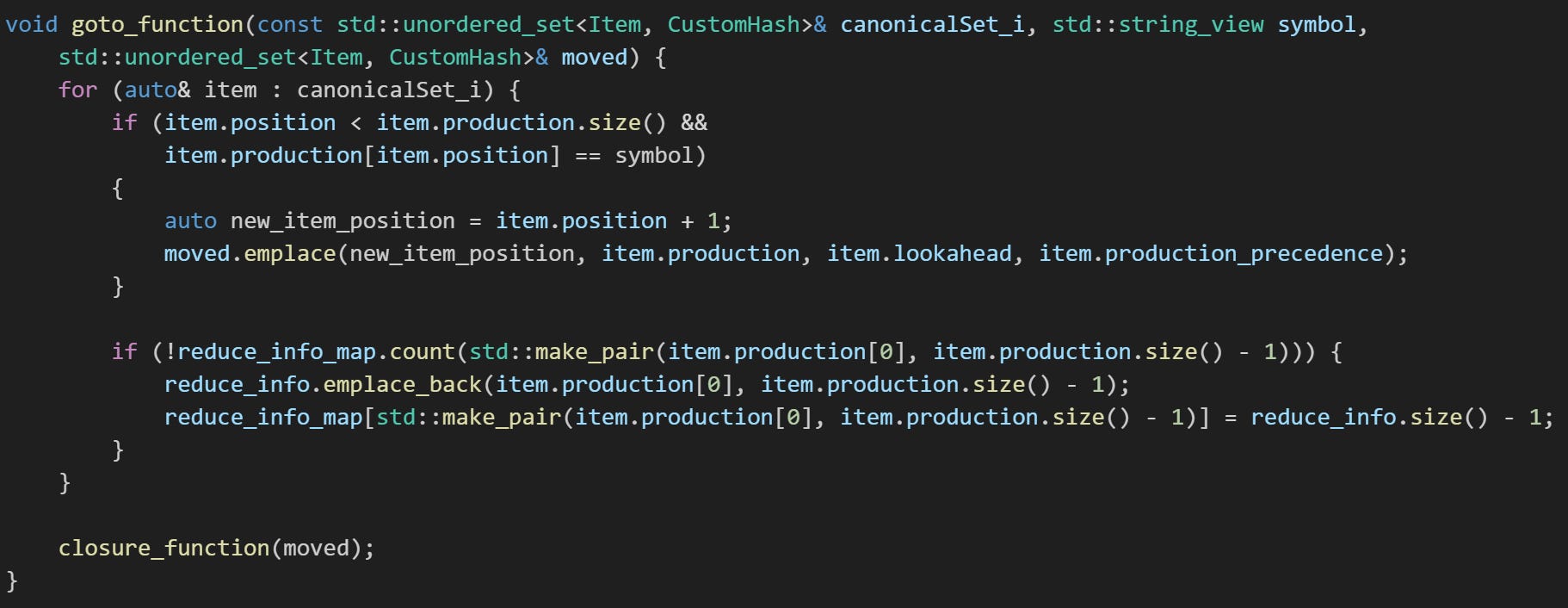
The second if-statement checks that a std::pair of the item production LHS (first symbol, at index 0), and the number of symbols in the RHS, exists in the member variable reduce_info_map. This mapping will be used to specify the number of symbols to be popped off the parser stack during reduction when constructing the parse tables.
That’s all for the helper functions. Back to build_cc().
build_cc() starts off with invoking the closure function with an item for the goal production and goal lookahead, generating all the other items that it implies. These items make up the initial and only (at the time) set of the canonical collection.

Next, the goto function is invoked on all the items in this initial set, generating another set of items as a result. If this new set is not in the canonical collection, it is added to the canonical collection. When a set gets processed completely, that is, goto function has been invoked on all the items in it, the set is marked “true”.
Next, building the parse tables.
A parsing context refers to the state of the parser at a given moment while analyzing an input string.
Goal > List
List > List Pair
List > Pair
Pair > ( Pair )
Pair > ( )Pair > ( Pair )
Pair > ( )